
小巧。快速。可靠。
三选二。
三选二。
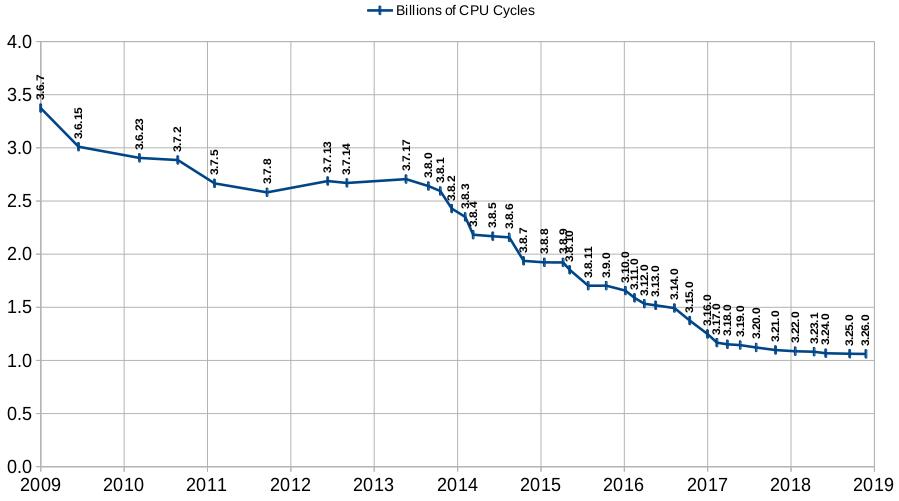
下图显示了 SQLite 在标准工作负载下使用的 CPU 周期数,涵盖了大约 10 年前的 SQLite 版本。与旧版本相比,最新版本的 SQLite 使用的 CPU 周期数大约减少了三分之二。
本文介绍了 SQLite 开发人员如何测量 CPU 使用率、这些测量结果的实际含义以及 SQLite 开发人员在其持续改进 SQLite 库 CPU 使用率的努力中所采用的技术。
简而言之,SQLite 的 CPU 性能测量方法如下:
为了进行性能测量,SQLite 的编译方式与生产系统中的编译方式大致相同。这里所说的“大致相同”是因为 SQLite 在生产环境中的每一个应用场景都不同。一个系统使用的编译时选项不一定与其他系统相同。关键在于避免那些会显著影响生成的机器码的选项。例如,-DSQLITE_DEBUG 选项被省略,因为该选项会在 SQLite 库性能关键部分的中间插入数千个 assert() 语句。-pg 选项(在 GCC 中)也被省略,因为它会导致编译器发出额外的概率性能测量代码,从而干扰实际的性能测量。
在性能测量中,使用 -Os 选项(优化代码大小)而不是 -O2 选项,因为 -O2 选项会进行大量的代码移动,使得难以将特定的 CPU 指令与 C 源代码行关联起来。
“典型”工作负载由 SQLite 标准源代码树中的 speedtest1.c 程序生成。该程序力求以真实世界应用的典型方式使用 SQLite 库。当然,每个应用程序都不同,因此没有一个测试程序能够完全模拟所有应用程序的行为。
随着 SQLite 开发人员对“典型”用法的理解不断发展,speedtest1.c 程序也会不时更新。
标准源代码树中的 speed-check.sh shell 脚本用于运行 speedtest1.c 程序。要复制性能测量结果,请将以下文件收集到一个目录中:
然后运行 "sh speed-check.sh trunk"。
使用 Cachegrind 测量性能,因为它可以提供可重复性高达 7 位或更多有效数字的结果。相比之下,实际(挂钟)运行时间几乎无法重复到一位有效数字以外。
cachegrind 的高重复性允许 SQLite 开发人员实现和测量“微优化”。微优化是对代码的修改,导致性能略有提升。典型的微优化会将 CPU 周期数减少 0.1% 或 0.05% 甚至更少。这种改进用实际运行时间几乎无法测量。但是,数百或数千次微优化累积起来,就会产生可测量的实际性能提升。
当 SQLite 开发人员编辑 SQLite 源代码时,他们会运行 speed-check.sh shell 脚本以跟踪更改对性能的影响。该脚本编译 speedtest1.c 程序,在 cachegrind 下运行它,使用 cg_anno.tcl TCL 脚本处理 cachegrind 输出,然后将结果保存到一系列文本文件中。speed-check.sh 脚本的典型输出如下所示:
==8683== ==8683== I refs: 1,060,925,768 ==8683== I1 misses: 23,731,246 ==8683== LLi misses: 5,176 ==8683== I1 miss rate: 2.24% ==8683== LLi miss rate: 0.00% ==8683== ==8683== D refs: 557,686,925 (361,828,925 rd + 195,858,000 wr) ==8683== D1 misses: 5,067,063 ( 3,544,278 rd + 1,522,785 wr) ==8683== LLd misses: 57,958 ( 16,067 rd + 41,891 wr) ==8683== D1 miss rate: 0.9% ( 1.0% + 0.8% ) ==8683== LLd miss rate: 0.0% ( 0.0% + 0.0% ) ==8683== ==8683== LL refs: 28,798,309 ( 27,275,524 rd + 1,522,785 wr) ==8683== LL misses: 63,134 ( 21,243 rd + 41,891 wr) ==8683== LL miss rate: 0.0% ( 0.0% + 0.0% ) text data bss dec hex filename 523044 8240 1976 533260 8230c sqlite3.o 220507 1007870 7769352 sqlite3.c
输出中重要的部分(开发人员最关注的部分)以红色显示。基本上,开发人员想知道编译后的 SQLite 库的大小以及运行性能测试所需的 CPU 周期数。
来自 cg_anno.tcl 脚本的输出显示了每行代码消耗的 CPU 周期数。该报告大约有 80,000 行。下面是从报告中间提取的一小段示例,以显示其外观:
. SQLITE_PRIVATE int sqlite3BtreeNext(BtCursor *pCur, int *pRes){
. MemPage *pPage;
. assert( cursorOwnsBtShared(pCur) );
. assert( pRes!=0 );
. assert( *pRes==0 || *pRes==1 );
. assert( pCur->skipNext==0 || pCur->eState!=CURSOR_VALID );
369,648 pCur->info.nSize = 0;
369,648 pCur->curFlags &= ~(BTCF_ValidNKey|BTCF_ValidOvfl);
369,648 *pRes = 0;
739,296 if( pCur->eState!=CURSOR_VALID ) return btreeNext(pCur, pRes);
1,473,580 pPage = pCur->apPage[pCur->iPage];
1,841,975 if( (++pCur->aiIdx[pCur->iPage])>=pPage->nCell ){
4,340 pCur->aiIdx[pCur->iPage]--;
5,593 return btreeNext(pCur, pRes);
. }
728,110 if( pPage->leaf ){
. return SQLITE_OK;
. }else{
3,117 return moveToLeftmost(pCur);
. }
721,876 }
当然,左侧的数字是该行代码的 CPU 周期计数。
cg_anno.tcl 脚本从默认的 cachegrind 注释输出中删除了多余的细节,以便可以使用并排差异比较前后报告,以查看微优化尝试如何影响性能的具体细节。
使用标准化的 speedtest1.c 工作负载和 cachegrind 已实现了显著的性能改进。但是,必须认识到这种方法的局限性:
性能测量是在单个编译器(gcc 5.4.0)、优化设置(-Os)和单个平台(Ubuntu 16.04 LTS 上的 x64 架构)上完成的。其他编译器和处理器的性能可能会有所不同。
正在测量的 speedtest1.c 工作负载试图代表各种典型的 SQLite 用法。但是,每个应用程序都不同。speedtest1.c 工作负载可能不是某些应用程序执行的活动类型的良好代理。SQLite 开发人员一直在努力改进 speedtest1.c 程序,使其更好地模拟实际的 SQLite 使用情况。欢迎社区反馈。
cachegrind 提供的周期计数是实际性能的良好代理,但并非 100% 准确。
这里只测量 CPU 周期计数。CPU 周期计数是能耗的良好代理,但并不一定与实际运行时间很好地相关。进行 I/O 所花费的时间不会反映在 CPU 周期计数中,并且在许多 SQLite 使用场景中,I/O 时间占主导地位。
此页面上次修改于 2022-01-08 05:02:57 UTC